


My Buffalo, a 400 MHz, power-efficient ARM system (it consumes about 17W on average). The duo: two SATA disks (1TB each) running in RAID-1 configuration. The system can also act as a print server: most cheap home laser printer are not stand-alone device (lacking PostScript capability) and need to be attached to a PC in order to print, instead we can connect printer to this Buffalo box via usb and serve printing over network.
 y newest toy: a Buffalo LinkStation Duo Network Attached Storage (NAS – or a poor man’s home server). Had thought about this long ago but don’t have time till now to dig a little bit low-level to get the thing to work! Basically what I want to have is a miniature general-purpose home server, which would run continuously 24/7. But you know with the temperature and electricity conditions here in HCMC, most PC would surely break down if let running continuously for a few months. The idea is to hack this NAS device to run Debian and turn it into a hybrid system: NAS (file server, torrent, UPnP…) and a home server which would handle a little more extra tasks. I took me a whole night to figure out how to do it.
y newest toy: a Buffalo LinkStation Duo Network Attached Storage (NAS – or a poor man’s home server). Had thought about this long ago but don’t have time till now to dig a little bit low-level to get the thing to work! Basically what I want to have is a miniature general-purpose home server, which would run continuously 24/7. But you know with the temperature and electricity conditions here in HCMC, most PC would surely break down if let running continuously for a few months. The idea is to hack this NAS device to run Debian and turn it into a hybrid system: NAS (file server, torrent, UPnP…) and a home server which would handle a little more extra tasks. I took me a whole night to figure out how to do it.
1. Boot the device via tftp, using u-boot, the universal bootloader. We need to to erase the HDD’s partition table (with something like: dd if=/dev/zero of=/dev/sd[a/b] count=1) to force the device into tftp boot.
2. Telnet to the device and prepare the disks: using fdisk to apply a same partition structure to both two disks (/dev/sda and /dev/sdb) with the usual Linux FS: /boot, /swap, /(root), and /data). The disk structure would appear like this:
/dev/sda1 1 6 48163 fd Linux raid
/dev/sda2 7 1200 9590805 fd Linux raid
/dev/sda4 1201 60801 478745032 85 Linux extended
/dev/sda5 1201 1329 1036161 82 Linux swap
/dev/sda6 1330 60801 477708808 fd Linux raid
3. Setup the RAID-1 (one-to-one mirror) structure, you can see that we mirror /boot (sda1, sdb1), /(root) (sda2, sdb2), and /data (sda6, sdb6), there’s no need to mirror /swap:
mdadm –create /dev/md1 –level=1 –raid-devices=2 /dev/sda2 /dev/sdb2
mdadm –create /dev/md2 –level=1 –raid-devices=2 /dev/sda6 /dev/sdb6
4. Install Debian (Lenny) using debootstrap, a very handy tool to install Debian directly from a repository. DeBootStrap pulls the packages over network, build a new rootfs, after chroot-ing to the newly build system, pull and build the kernel from source. After that, we can use regular Debian commands to update, configure network, add softwares, etc… After rebooting, we’d got a brand new Debian with 1TB of RAID-1 disk space, which runs flawlessly and which is ready to serve my various automation tasks!
Notes: installing Debian would void the warranty and could easily brick your device, use the information at your own risk. The steps here are just summary, there’s been various try and fail to get the thing done, e.g: we need priorly to have binutils, wget, zlib and libssl binaries for debootstrap to work (download the deb files from Lenny’s repository, extract and copy over the Buffalo), after debootstrap-ing, I forgot to set the root password, and unable to login when the machine reboot, thus having to start the whole process over again 😢. For further details, please consult the Buffalo NAS community.
UPDATE, Nov 18th, 2010
For a NAS which runs 24/7, it’s critical to monitor system status (temperature and the moving parts). I wrote this little fand script, a daemon to monitor hard disk temperature and adjust the fan’s speed accordingly. HDD’s temperature can be retrieved using smartmontools (most hard disk nowadays has S.M.A.R.T capabilities). And fan control on Buffalo LS Duo is done via the gpio module (thanks to talent hackers on the Buffalo NAS forum), something like this:
$ echo ‘slow’> /proc/linkstation/gpio/fan
I’ve defined some thresholds, in a tropical country like VN, room temperature around 30° ~ 35° (Celsius) is a common thing, so if the HDD’s temperature is below 35°, we would turn off the fan. If it is between 35° ~ 40°, the fan speed would be ‘slow’, from 40° to 45°, the fan will be turned to ‘fast’, and if temperature excesses 45°, fan speed is set to ‘full’. Well, and even if 50° is reached, we would send a notification email (via sendmail) and shutdown the system. If you find it interesting, here is the fand scripts.
UPDATE, Nov 20th, 2010 (THE REAL DUO)
To pair with the Link-Station NAS is its cousin also from Buffalo, the Link-Theater LT-H90LAN. The LT-H90LAN reads media from Samba shares or DLNA server via LAN and is a 720p and 1080i HD-ready device. Although not Full-HD (1080p), that’s enough for my need (I don’t have a Full-HD TV in my house anyhow, maybe I’m waiting for 3D home video). It’s quite pleasing to enjoy good video quality and excellent audio in your living room, all streaming from a central NAS. The box also runs a variant of Linux (though hacking can be a pain, I would only left the device untouched for safe). This is one further step toward an all-Linux-devices home (thought I should buy an OpenMoko phone then).




 fter years in IT career facing monitors, it’s now time to care a little about your eyes, and I’m now using my Kindle for reading news, documents everyday! However web browsing on Kindle is quite inconvenient, there’s of course no touch screen (imagine how touch would look like with a 3fps responsiveness display), and the 5-ways button make web pages’ navigation a kind of clumsiness! I was thinking about some form of automation, basically we would need to convert some news-feeds into Kindle’s native format (mobi) for the ease of our reading, the steps below:
fter years in IT career facing monitors, it’s now time to care a little about your eyes, and I’m now using my Kindle for reading news, documents everyday! However web browsing on Kindle is quite inconvenient, there’s of course no touch screen (imagine how touch would look like with a 3fps responsiveness display), and the 5-ways button make web pages’ navigation a kind of clumsiness! I was thinking about some form of automation, basically we would need to convert some news-feeds into Kindle’s native format (mobi) for the ease of our reading, the steps below: DK, the Kindle’s Software Development Kit has been released for quite some times but Amazon still strictly restrict accessing to it, many many software developers (like me) have registered and received no reply. It is understandable that Amazon could be skeptical on what to put on Kindle’s app store, but it should not be that conservative toward the developing community. KDK is basically just a PBP (Personal Basic Profile) J2ME (Java Micro Edition) with Amazon’s extension, a Kindle emulator, and some tools…
DK, the Kindle’s Software Development Kit has been released for quite some times but Amazon still strictly restrict accessing to it, many many software developers (like me) have registered and received no reply. It is understandable that Amazon could be skeptical on what to put on Kindle’s app store, but it should not be that conservative toward the developing community. KDK is basically just a PBP (Personal Basic Profile) J2ME (Java Micro Edition) with Amazon’s extension, a Kindle emulator, and some tools…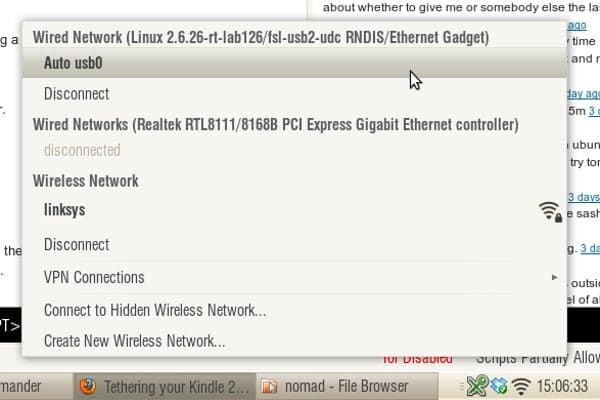
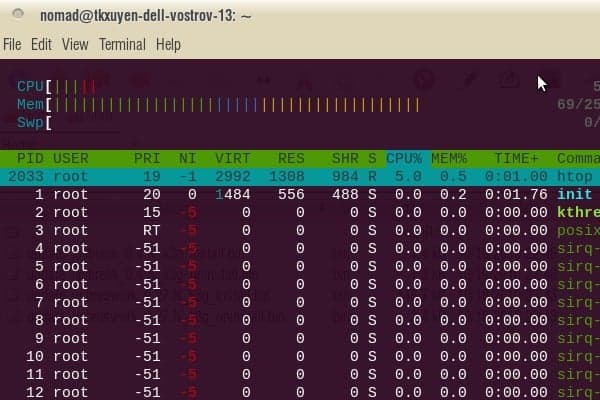

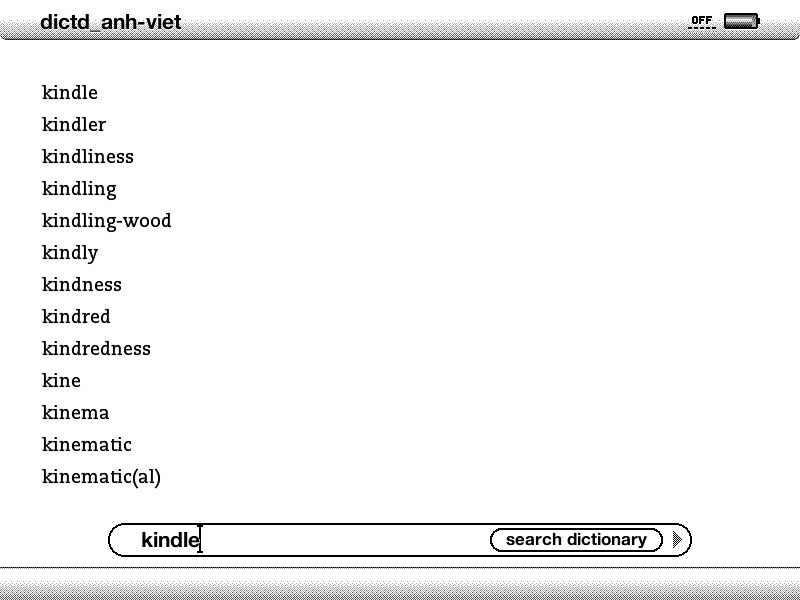



 an not resist to this temptation anymore. Kindle price dropped significantly lately and it’s time to pick a e-ink display book reader for myself. I’ve been curious about
an not resist to this temptation anymore. Kindle price dropped significantly lately and it’s time to pick a e-ink display book reader for myself. I’ve been curious about 
 hatever happened to programming? Điều gì đã xảy ra với lập trình? Khi ở năm 1 đại học (1998), tôi có viết một 3D engine đơn giản bằng Borland C, lúc đó sách vở thiếu, internet thì chưa có. Mục tiêu đặt ra rất đơn giản: hiển thị (xoay) một đối tượng 3D đọc từ file mô tả tọa độ các đỉnh. Bằng những hình dung hình học đơn giản, tôi xây dựng một phép chiếu: giao điểm của đường thẳng từ mắt tới các đỉnh của vật thể với mặt phẳng chiếu chính là pixel được hiển thị trên màn hình. Sau đó ít lâu đọc thêm tài liệu, tôi mới biết đó gọi là: phép chiếu phối cảnh – perspective projection. Một số đoạn code released từ game Doom giúp tôi hiểu rõ hơn kỹ thuật chiếu dùng trong game thực:
hatever happened to programming? Điều gì đã xảy ra với lập trình? Khi ở năm 1 đại học (1998), tôi có viết một 3D engine đơn giản bằng Borland C, lúc đó sách vở thiếu, internet thì chưa có. Mục tiêu đặt ra rất đơn giản: hiển thị (xoay) một đối tượng 3D đọc từ file mô tả tọa độ các đỉnh. Bằng những hình dung hình học đơn giản, tôi xây dựng một phép chiếu: giao điểm của đường thẳng từ mắt tới các đỉnh của vật thể với mặt phẳng chiếu chính là pixel được hiển thị trên màn hình. Sau đó ít lâu đọc thêm tài liệu, tôi mới biết đó gọi là: phép chiếu phối cảnh – perspective projection. Một số đoạn code released từ game Doom giúp tôi hiểu rõ hơn kỹ thuật chiếu dùng trong game thực:  n my
n my 



 ecently, the wonderful
ecently, the wonderful 
 echnical debt là một ẩn dụ đôi khi được dùng trong ngành công nghệ phần mềm (CNPM), và là ẩn dụ đúng nhất cho thực trạng CNPM Việt Nam hiện tại. Phát triển phần mềm cũng như mọi công việc kinh doanh khác, về bản chất giống việc vay nợ, tức hiệu suất sinh lời phải đủ để trả lãi và quay vòng vốn trong một khoảng thời gian nhất định. Dĩ nhiên các yếu tố kỹ thuật khó lòng có thể được định lượng như tiền bạc, nhưng theo một nghĩa nào đó, nếu tỉ lệ các vấn đề được giải quyết thấp hơn so với tỉ lệ các vấn đề phát sinh, thì điều đó có nghĩa là dự án đang “tăng trưởng âm”. Tuy mượn một thuật ngữ từ lĩnh vực kinh tế, song “nợ kỹ thuật” thuần túy đề cập các vấn đề kỹ thuật như được trình bày sau đây:
echnical debt là một ẩn dụ đôi khi được dùng trong ngành công nghệ phần mềm (CNPM), và là ẩn dụ đúng nhất cho thực trạng CNPM Việt Nam hiện tại. Phát triển phần mềm cũng như mọi công việc kinh doanh khác, về bản chất giống việc vay nợ, tức hiệu suất sinh lời phải đủ để trả lãi và quay vòng vốn trong một khoảng thời gian nhất định. Dĩ nhiên các yếu tố kỹ thuật khó lòng có thể được định lượng như tiền bạc, nhưng theo một nghĩa nào đó, nếu tỉ lệ các vấn đề được giải quyết thấp hơn so với tỉ lệ các vấn đề phát sinh, thì điều đó có nghĩa là dự án đang “tăng trưởng âm”. Tuy mượn một thuật ngữ từ lĩnh vực kinh tế, song “nợ kỹ thuật” thuần túy đề cập các vấn đề kỹ thuật như được trình bày sau đây: