KDK, the Kindle’s Software Development Kit has been released for quite some times but Amazon still strictly restrict accessing to it, many many software developers (like me) have registered and received no reply. It is understandable that Amazon could be skeptical on what to put on Kindle’s app store, but it should not be that conservative toward the developing community. KDK is basically just a PBP (Personal Basic Profile) J2ME (Java Micro Edition) with Amazon’s extension, a Kindle emulator, and some tools…
Having no KDK doesn’t mean that we can not develop software for Kindle! Below are my notes on building, deploying an example application for Kindle. This would make cleared the steps needed to write applications for Kindle without the KDK. Please notes: the information is collected from many different sources, jailbreaking could be considered “illegal” according to some Term Of Use. Use the information at your own risk!
1. Jailbreaking and usbnetwork
Download kindle-jailbreak and kindle-usbnetwork from here. Choose the files that is suitable for your device, e.g: for my Kindle 3 (wifi + 3G), it would be the jailbreak_0.4.N_k3g and usbnetwork_0.27.N_k3g. Copy the jailbreak_0.4.N_k3g file to your Kindle, then proceed to updating the system. The jailbreak exploits a hole in Busybox implementation to gain root access. Next, do the same thing with usbnetwork_0.27.N_k3g, which provides a secure shell via USB connection.
Launch the Search box on our Kindle, type ;debugOn, press enter to execute the command, then do the same thing with ~usbNetwork to start the sshd daemon. The default configuration would set Kindle to 192.168.2.2 and expect the connected PC to be 192.168.2.1. Now we’ve got root access and the entire FS (file system) in the palms of our hands. Spend some times exploring it, when done, put the Kindle back to normal use by issuing ~usbNetwork again, then ;debugOff.
2. Key and file signing
This is the most important part! Kindle’s “kindlets” are exactly Java’s jar file with .azw2 extension, however, we can’t just simply copy and run it. The applet is linked against several system libraries located at: /opt/amazon/ebook/lib/Kindlet-1.1.jar and /opt/amazon/ebook/sdk/lib/*.jar (copy these files to your PC for local jar building in place of those provided by the KDK).
The .azw2 file must also be signed with 3 different keys located at: /var/local/java/keystore/developer.keystore and the security policy is defined at: /opt/amazon/ebook/security/. For more information on signing, please refer to this post. If you’re tweaking your Kindle and writing apps for it, I suggest that we would just use the signing key of Andrew de Quincey, the first one to figure out about this, so that free softwares can be easily shared among Kindle’s users.
Configure the usbnetwork interface and access Kindle via sshd. Image below: the command htop running on Kindle’s ssh console.
When finished with hacking, we can un – install these two exploits to restore Kindle back to original state (and receive official updates from Amazon), but that would be after the next section, when we’d been able to deploy our own software on it!
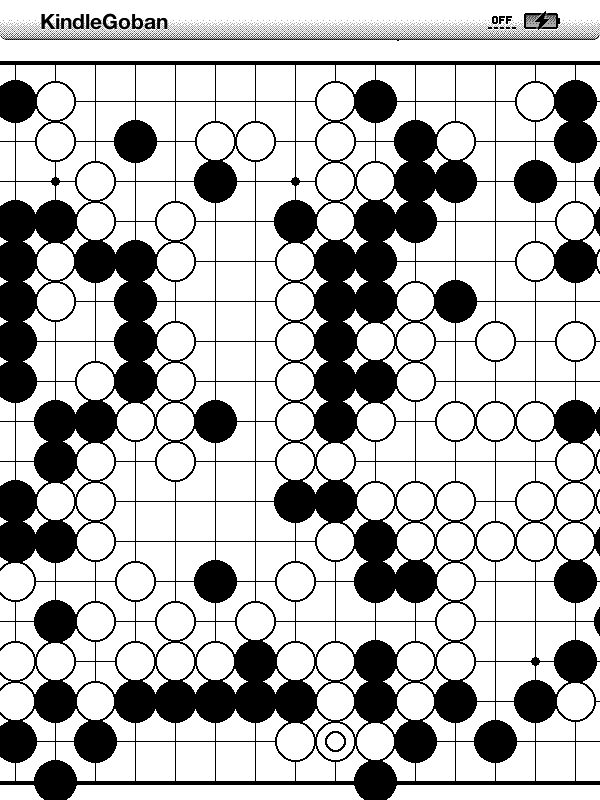
3. KindleGoban – an example app
I’m going to deploy KindleGoban, a Go (weiqi) game viewer, as an example app. Adrian Petrescu, the man behind this open source game, is perhaps, an insider of Amazon’s KDK project. But technically he’s under a NDA (non disclosure agreement) and won’t be able to say anything except the publicly available information. However, he did indirectly provide valuable resources.
First, copy the developer_keystore (mentioned in #2) to your PC & Kindle (at /var/local/java/keystore/developer.keystore). Then download KindleGoban (and its dependency library KWT. Make some changes to the build.xml to include KWT (adding several widgets) and get rid of the KDK’s stuffs (which we don’t have). Then build, sign and deploy the .azw2 file to your Kindle. And there you are, a nice Go game viewer!
$ ant build.xml
$ jar cvfm KindleGoban.azw2 KindleGoban.mf bin/*
$ ./signkindlet developer_keystore KindleGoban.azw2
# copy the file over to your Kindle, also need
# to copy an example .sgf file for testing
$ scp KindleGoban.azw2 root@192.168.2.2:/mnt/us/documents
4. Resources
This section gonna be regularly updated on the availability of documents, tools.. for development on Kindle. Please note most of these are from third – parties rather than Amazon, which are the results of hacking, reverse – engineering… and some other information indirectly available from the KDK. At the moment, we only have this official javadoc from Amazon which describes the KDK’s APIs.
- Savory: a native ebook converting daemon for Kindle.
- Kindle emulator: need to double check this.
- KWT: Kindle Widget Toolkit.
- Mangle: a manga viewer for Kindle.
- Qindle: a Qt port for Kindle.

KindleGoban screenshots, this is, like most Kindle projects at the moment, is just starting, would expect more features in the time coming.